Как накачать средние дельты: Как накачать средние дельты | Strong life
Упражнения на среднюю дельту: как делать правильно
Средняя дельта – это уникальный мышечный пучок, который включается в работу практически при выполнении любого упражнения на плечи. Бытует много разногласий по поводу необходимости выполнения каких-либо отдельных упражнений для данного пучка, но можно сказать точно: для тренировки средней дельтовидной мышцы существуют как базовые, так и изолирующие подходы. Чтобы нагрузка была правильной, необходимо обратиться к анатомии.
Содержание
- Анатомия и функции средней дельты
- Базовое упражнение: жим штанги из-за головы
- Классическая изоляция: махи с гантелями стоя
- Жим Арнольда
- Несколько советов по домашним тренировкам
- Полезное видео: как тренировать средние дельты
Анатомия и функции средней дельты
Согласно анатомическим справочникам, дельтовидная мышца выполняет основную функцию спинного участка – отвечает за работу лопаток. И на нагрузку дельтовидных мышц напрямую влияет положение плечевого сустава.
- При опущенных руках и движении лопаток работает задняя дельта;
- при поднятых – передняя;
- средний пучок выполняет связующую роль, получившую название синергиста.
Данный отдел наиболее эффективно работает с задней дельтой, потому что находится ближе всего к ней. Но для полной изоляции, выполняя упражнения на средние дельты, следует уменьшить угол по отношению к заднему пучку.
Базовое упражнение: жим штанги из-за головы
Лучшие упражнения на среднюю дельту начинаются с базы, которая, в обязательном порядке, выполняется всеми категориями атлетов: от новичка и до профессионала.
Для лучшего контроля локтей, данные упражнения на среднюю дельту плеча советуют выполнять перед зеркалом. Выбирать следует сидячее положение, так как при жиме штанги стоя в процесс включаются ноги, и плечевая мышечная группа получает недостаточную нагрузку.
Техника выполнения:
- Сядьте на скамью, широко расставьте ноги для надёжного упора.
 Во время выполнения упражнения спину прогибать нельзя.
Во время выполнения упражнения спину прогибать нельзя. - Хват больше ширины плеч, мягко поднимите штангу над головой.
- Опускайте штангу за спину до того момента, пока не образуется прямой угол в локтевом суставе.
- Выжмите штангу над головой.
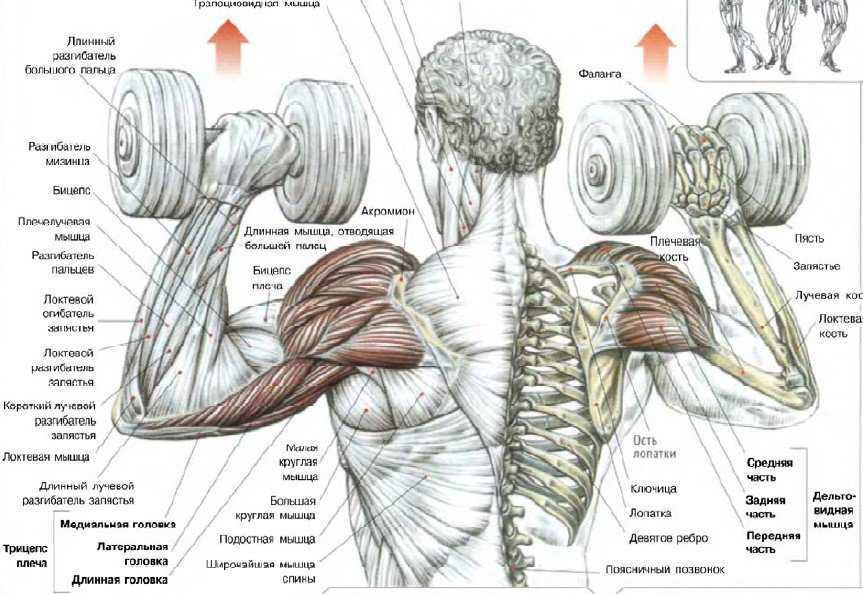 Во время выполнения упражнения спину прогибать нельзя.
Во время выполнения упражнения спину прогибать нельзя.Выполняя упражнения для среднего пучка дельт не следует слишком увлекаться весами, это может привести к травме.
На начальном этапе внимание необходимо уделить технике выполнения и только после этого переходить к постепенному добавлению лишних килограмм.
Классическая изоляция: махи с гантелями стоя
Махами лучше всего заканчивать тренировку средней дельты плеча, это поможет немного растянуть средние пучки. По принципу данное упражнение очень похоже на разводку гантелей лежа – растягивает мышечные волокна, и тренирует мышечную группу в целом.
Как накачать среднюю дельту с помощью махов:
- Встаньте ровно, выпрямите спину. Можно взять в каждую руку по гантели или выполнять поочерёдно, наиболее эффективно, так как способствует большей концентрации на действии.
- Сделайте мах гантелей до уровня плеча. Задерживать в верхней точке руку не стоит.
- Верните руку в исходное положение. Возврат должен выполняться постепенно, без рывков, и занимать в 2 раза больше времени чем подъём.
 Можно взять в каждую руку по гантели или выполнять поочерёдно, наиболее эффективно, так как способствует большей концентрации на действии.
Можно взять в каждую руку по гантели или выполнять поочерёдно, наиболее эффективно, так как способствует большей концентрации на действии.Важно! Чтобы выполнить правильно такие упражнения на средний пучок дельт, следует подобрать подходящий вес.
При слишком большой нагрузке атлет перестаёт обращать внимание на технику: появляются рывки, гантель может не доходить до уровня плеча, корпус постепенно наклоняется вперёд. При таких ошибках упражнение теряет качество изолирующего, и нагрузка распространяется на остальные группы мышц.
Жим Арнольда
Также, как и махи в стороны, жим Арнольда является классическим изолирующим упражнением и позволяет качественно прокачать средний пучок дельт.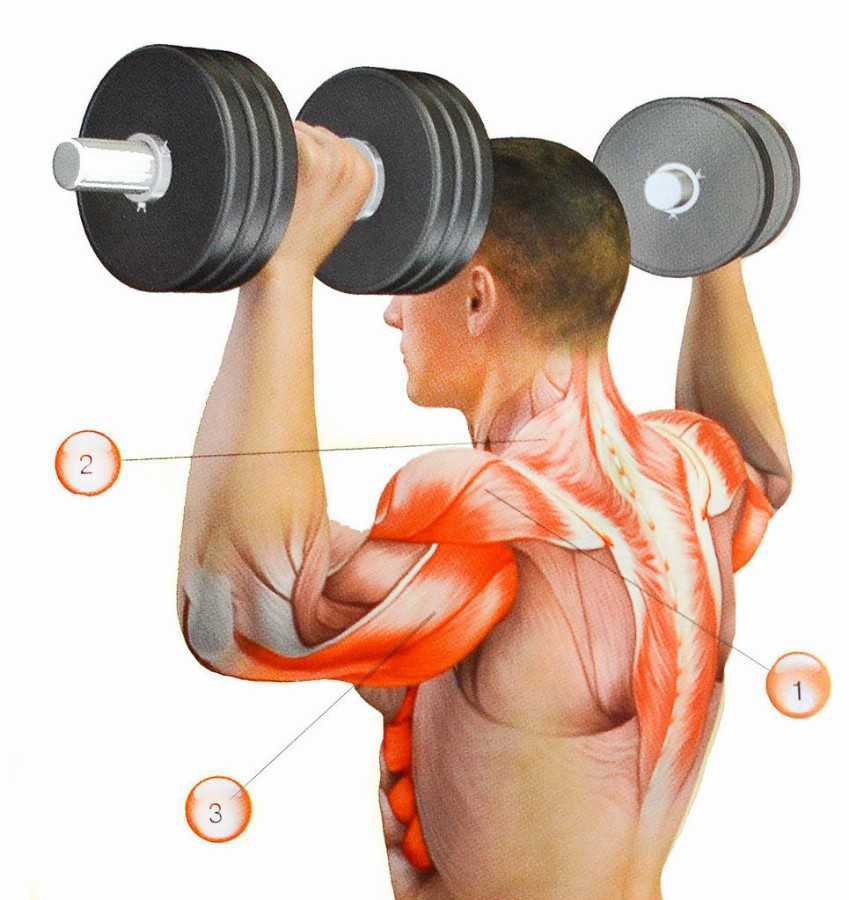 Многие атлеты советуют выполнять жим Арнольда стоя, но возникает такая же проблема, как и при жиме штанги из-за головы – неосознанно в работе начинают участвовать другие мышечные группы, и тренировка средней дельты теряет своё качество. Поэтому лучше всего для данной разновидности жимов выбрать гимнастическую скамью.
Многие атлеты советуют выполнять жим Арнольда стоя, но возникает такая же проблема, как и при жиме штанги из-за головы – неосознанно в работе начинают участвовать другие мышечные группы, и тренировка средней дельты теряет своё качество. Поэтому лучше всего для данной разновидности жимов выбрать гимнастическую скамью.
Правильное выполнение:
- Изначальное положение: гантели зажаты перед собой на уровне груди. Спина прямая, голову не опускать.
- Сделать жим над головой, но во время движения вверх, гантели следует развернуть на 180 градусов.
- Достигнув верхней точки, в обратной последовательности руки следует вернуть в исходное положение.
Не надо фиксировать гантели в верхней точки, это приводит только к лишней трате сил. Выполняя жим Арнольда можно подобрать вес немного больше среднего, но не следует сразу переходить на профессиональные тяжести.
Несколько советов по домашним тренировкам
Выполнять упражнения на среднюю дельту можно и дома, даже без инвентаря. Это поможет немного укрепить мышечную группу, а потом пойти в тренажёрный зал и продолжить уже там раскрывать свой потенциал.
Это поможет немного укрепить мышечную группу, а потом пойти в тренажёрный зал и продолжить уже там раскрывать свой потенциал.
Упражнение простое, требует наличие трёх табуретов.
Два табурета расставляются на расстояние немного шире плеч, а на третий необходимо закинуть ноги.
- Таким образом получается домашняя импровизация брусьев.
- Делай «раз»: руки сгибаются в локтях.
- Делай «два»: распрямляются.
Так как упражнение выполняют без веса, то насчёт количества можно не переживать – отжимайтесь до тех пор, пока хватит сил. Это универсальный вариант отжимания и делать его можно практически каждый день, давая себе пару дней отдыха в неделю.
Конечно, выполняя такое упражнение, средние пучки дельтовидных мышц не получают требуемой изоляции — часть нагрузки израсходуется на передний и задний пучок. Чтобы результат был более качественным, следует приобрести гантели и выполнять упражнения, которые описаны выше.
Полезное видео: как тренировать средние дельты
О том, какие упражнения следует выполнять на передние дельты, читайте в этой статье →
Тренировка дельтовидных мышц →
Упражнения на передние, задние и средние дельты от тренеров Gold’s Gym
Совет от Gold’s Gym
Упражнения принесут больший эффект, если прорабатывать каждую группу дельтовидных мышц в отдельный тренировочный день.
Накачанные мышцы плеч привлекают внимание не менее, а порой даже более чем пресловутый упругий пресс — особенно это касается мужчин. Но и прекрасной половине человечества не помешает время от времени уделять внимание развитию этой части тела, ведь подтянутые мышцы плеч выглядят так соблазнительно.
Дельтовидные мышцы образованы тремя основными «пучками» — передними, задними и средними. Передняя дельта принимает участие практически во всех повседневных движениях рук. Часто она достаточно хорошо развита, поэтому ей принято уделять меньше всего внимания. Сложнее проработать средние дельты, а ведь именно от них зависит ширина плеч. Самая же тяжелая задача — накачать задние дельты, формирующие объем. Только благодаря сбалансированной нагрузке на каждую группу мышц можно получить красивый «рисунок» плечевого пояса.
Передняя дельта принимает участие практически во всех повседневных движениях рук. Часто она достаточно хорошо развита, поэтому ей принято уделять меньше всего внимания. Сложнее проработать средние дельты, а ведь именно от них зависит ширина плеч. Самая же тяжелая задача — накачать задние дельты, формирующие объем. Только благодаря сбалансированной нагрузке на каждую группу мышц можно получить красивый «рисунок» плечевого пояса.
Прежде чем перейти к перечислению основных упражнений на развитие передних, боковых и задних пучков дельтовидной мышцы, выделим ключевые принципы тренировок:
- Тренировки на плечи должны быть не реже 1–2 раз в неделю.
- Каждая тренировка должна начинаться с разминки — для разогрева мышц используйте те же упражнения, но с меньшими весами.
- Жим является более эффективной тренировкой дельтовидных мышц, чем махи.
- В приоритете должны быть свободные веса, а не тренажеры.
- Начинайте комплекс упражнений на плечи с проработки задних дельт.
- Тренировка должна включать как минимум одно базовое упражнение, например, жим штанги из-за головы.
- Уделяйте особое внимание технике выполнения упражнений.
- Важно подобрать вес правильно. Например, известный культурист Ли Лабрада считает, что правильный вес тот, что на 10% ниже, чем в был использован в предыдущем подходе.
- Некоторые поклонники силового тренинга ошибочно считают, что дельтовидные мышцы следует качать после того, как будут основательно проработаны мышцы спины и груди. Но это не так. Наоборот — тяга, жим лежа, упражнения на спину требуют развитых дельт. В противном случае именно непроработанность дельт станет причиной замедленного развития соседних мышц.
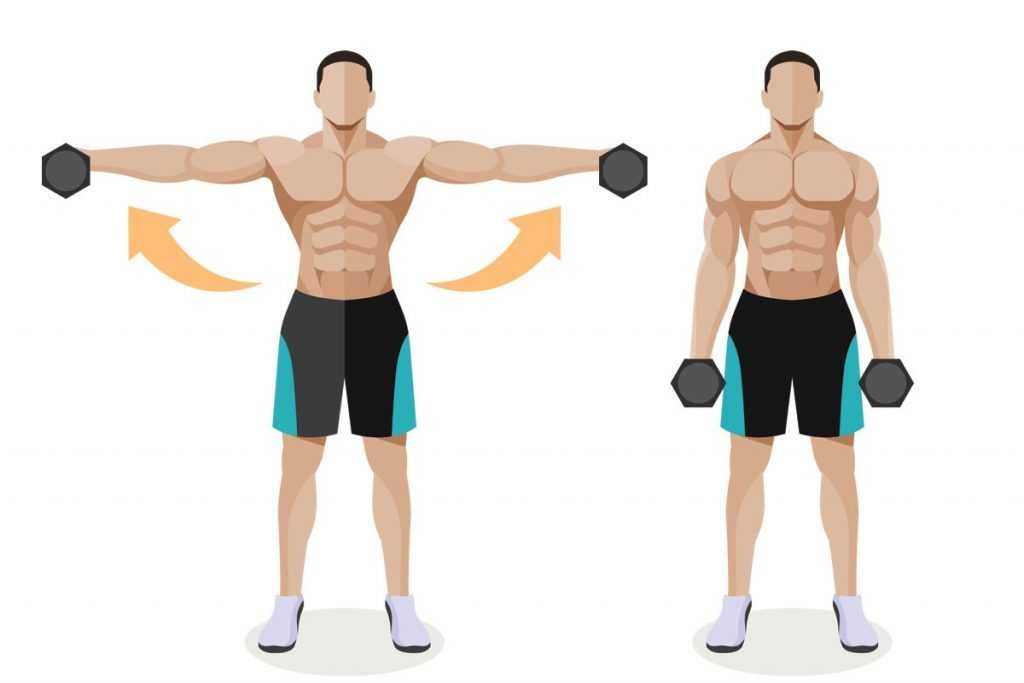
Упражнения на передние дельты
Тренировка на передние пучки дельтовидной мышцы должна иметь высокую интенсивность — используйте максимальный рабочий вес и среднее количество повторений. Не следует резко опускать гантели или штангу — постарайтесь выполнять негативную фазу упражнения медленнее.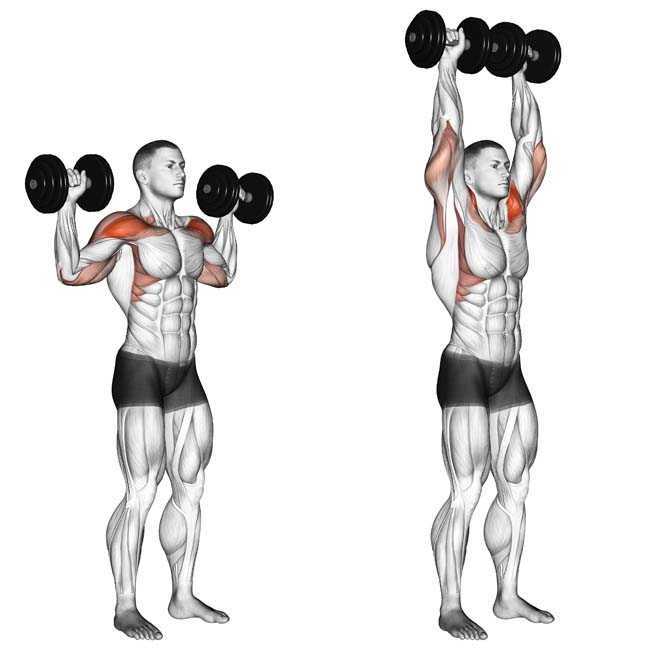
Упражнения на проработку фронтальных мышц:
- жим штанги от груди (армейский жим) и его вариации с гантелями. Оптимальный вариант — 3 подхода по 6 повторений;
- жим Арнольда с гантелями — 3 подхода по 8 повторений;
- подъем гантелей перед собой — поочередно или вместе, также возможна вариация со штангой. 3 подхода по 12 повторений.
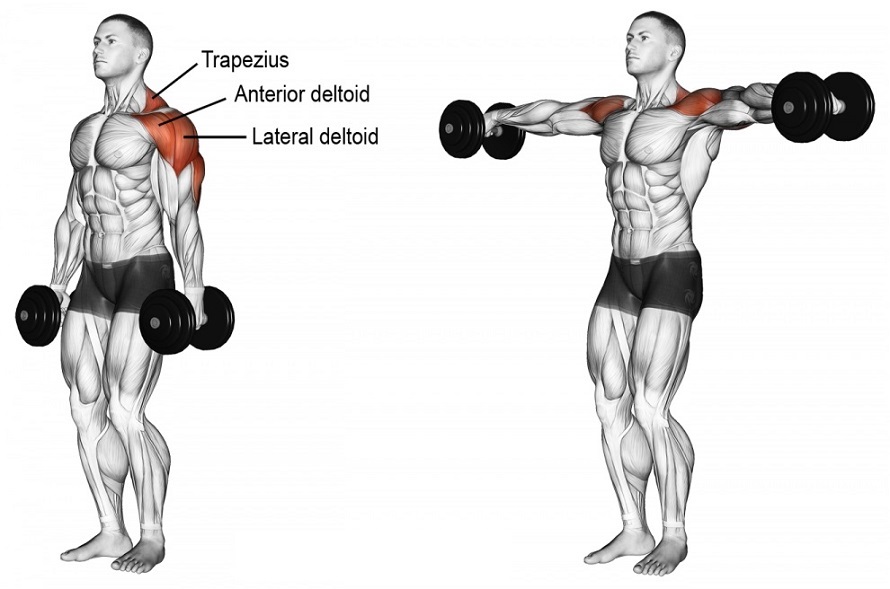
Упражнения на средние дельты
Совет от Gold’s Gym
Совместите упражнения на передние и средние дельты с проработкой мышц спины или ног, а упражнения на задние дельты — с тренировкой грудных мышц.
К наиболее эффективным можно отнести следующие упражнения:
- жим штанги от груди (армейский жим) — 3 подхода по 6 повторений;
- жим гантелей сидя — 3 подхода по 8 повторений;
- подъем гантелей стоя (через стороны) — 3 подхода по 12–15 повторений.
Упражнения на задние дельты
Как уже отмечалось, это сложнейший участок для раскачки, поэтому у начинающих атлетов он часто является самым непроработанным. Эффективных упражнений на задние дельты не так уж много. Ниже — самые популярные из них:
Эффективных упражнений на задние дельты не так уж много. Ниже — самые популярные из них:
- тяга гантелей лежа на животе — 3 подхода по 10 повторений;
- подъем гантелей в наклоне (через стороны) — 3 подхода по 15 повторений.
Куда записаться на тренировки по проработке дельтовидных мышц
Спортивный клуб мирового уровня Gold’s Gym поддерживает решение каждого стать сильнее, выносливее и стройнее. Здесь вас ожидают благоустроенные просторные залы, внимательные тренеры и индивидуальный подход к каждому клиенту, будь то новичок или профессиональный спортсмен. Сосредоточьтесь на достижении результата — а во всем остальном можете положиться на легендарный американский клуб.
Если вам недостаточно тренажерного зала, в Gold’s Gym к вашим услугам бассейн, теннисные корты, занятия боевыми искусствами и разнообразные программы тренировок на проработку всех мышц тела.
Databricks Delta Lake — дружественное введение | by Sertis
В этой статье представлены Databricks Delta Lake . Революционный уровень хранения, обеспечивающий надежность и повышающий производительность озер данных с помощью Apache Spark.
Революционный уровень хранения, обеспечивающий надежность и повышающий производительность озер данных с помощью Apache Spark.
Сначала мы рассмотрим сухие части, которые объясняют, что такое Apache Spark и озера данных, а также объясняют проблемы, связанные с озерами данных. Затем рассказывается об озере Дельта и о том, как оно решило эти проблемы с помощью практического и простого в применении руководства.
Apache Spark — это крупномасштабная система обработки данных и унифицированная аналитика для больших данных и машинного обучения. Первоначально он был разработан в Калифорнийском университете в Беркли в 2009 году. Apache Spark — это полностью открытый исходный код, размещенный в независимом от поставщика Apache Software Foundation.
Apache Spark обеспечивает высокую производительность как для -art DAG планировщик, оптимизатор запросов и механизм физического выполнения. Spark предлагает более 80 высокоуровневых операторов, упрощающих создание параллельных приложений, и вы можете использовать их в интерактивном режиме из оболочек Scala, Python, R и SQL.
Spark работает на Hadoop, Apache Mesos, Kubernetes, автономно или в облаке. Он может получить доступ к различным источникам данных. Вы можете запустить Spark, используя режим автономного кластера, на EC2, на Hadoop YARN, на Mesos или на Kubernetes. Доступ к данным в HDFS, Alluxio, Apache Cassandra, Apache HBase, Apache Hive и сотнях других источников данных.
Озеро данных — это центральное хранилище, в котором хранится большой объем данных в исходном необработанном формате, а также способ организации больших объемов самых разнообразных данных. По сравнению с иерархическим хранилищем данных, в котором данные хранятся в файлах или папках, в озере данных для хранения данных используется плоская архитектура.
Озеро данных содержит большие данные из многих источников в необработанном формате. Он может хранить структурированные, полуструктурированные или неструктурированные данные, которые можно хранить в более гибком формате, чтобы мы могли преобразовывать их при использовании для аналитики, науки о данных и машинного обучения.
Credits — Databricks
К сожалению, мы не живем в идеальном мире. Таким образом, большинство проектов озера данных терпят неудачу. Как вы уже догадались, создание озер данных — это проблема данных.
При работе с данными инженеры по данным, инженеры по машинному обучению и специалисты по данным сталкиваются с двумя проблемами: надежность и производительность.
Ненадежные данные низкого качества приводят к снижению производительности. Данные в большинстве случаев не готовы для обработки данных и машинного обучения, поэтому группы обработки данных заняты созданием сложных конвейеров для обработки полученных данных путем разделения, очистки и обработки, чтобы сделать их полезными для обучения моделей и бизнес-аналитики.
- Неудачные задания оставляют данные в поврежденном состоянии. Это требует утомительной очистки данных после неудачных заданий. К сожалению, доступные решения для облачного хранения не обеспечивают встроенной поддержки атомарных транзакций, что приводит к неполным и поврежденным файлам в облаке, что может нарушить выполнение запросов и заданий на чтение.
- Отсутствие применения схемы приводит к тому, что данные имеют несогласованную и некачественную структуру. Несоответствие типов данных между файлами или разделами вызывает проблемы с транзакциями и требует обходных путей для решения. Такие обходные пути используют тип string/varchar для всех полей, а затем приводят их к предпочтительному типу данных при выборке данных или применении транзакций OLAP (онлайн-аналитическая обработка).
- Отсутствие согласованности при одновременном добавлении и чтении или при пакетной и потоковой передаче данных в одно и то же место. Это связано с тем, что облачное хранилище, в отличие от RDMS, не совместимо с ACID.
- Несоответствие размера файла: либо слишком маленькие, либо слишком большие файлы. Наличие слишком большого количества файлов приводит к тому, что работники тратят больше времени на доступ, открытие и закрытие файлов при чтении, что влияет на производительность.
- Хотя секционирование полезно, оно может стать узким местом в производительности, если запрос выбирает слишком много полей.
- Низкая производительность чтения облачного хранилища по сравнению с хранилищем файловой системы. Пропускная способность облачного хранилища объектов/BLOB-объектов составляет от 20 до 50 МБ в секунду. В то время как локальные SSD могут достигать 300 МБ в секунду.

Итак, Delta Lake — движок следующего поколения, построенный на базе Apache Spark.
Delta Lake — это уровень хранения данных с открытым исходным кодом, обеспечивающий надежность озер данных. Он обеспечивает транзакции ACID, масштабируемую обработку метаданных и унифицирует потоковую и пакетную обработку данных. Delta Lake полностью совместим с API-интерфейсами Apache Spark. Вы можете легко использовать его поверх своего озера данных с минимальными изменениями, и да, это открытый исходный код! (Построен на стандартном паркете)
Озеро Delta обеспечивает надежность и производительность озер данных.
- Уплотнение : Delta Lake может повысить скорость запросов на чтение из таблицы путем объединения небольших файлов в более крупные.
- Пропуск данных: Когда вы записываете данные в дельта-таблицу, информация собирается автоматически. Delta Lake на Databricks использует эту информацию (минимальные и максимальные значения) для ускорения запросов. Вам не нужно настраивать пропуск данных, чтобы активировать эту функцию (если применимо).
- Кэширование: Дельта-кэширование ускоряет чтение за счет создания копий удаленных файлов в локальном хранилище узлов с использованием быстрого промежуточного формата данных. Данные кэшируются автоматически, когда файл извлекается из удаленного источника. Последовательные чтения одних и тех же данных выполняются локально, что приводит к значительному повышению скорости чтения.

- КИСЛОТНЫЕ транзакции: Наконец-то! Сериализуемые уровни изоляции гарантируют, что читатели никогда не увидят противоречивых данных, как в RDMS.
- Применение схемы: Delta Lake автоматически проверяет записываемую схему фрейма данных на совместимость со схемой таблицы. Перед записью из фрейма данных в таблицу Delta Lake проверяет, существуют ли столбцы в таблице во фрейме данных, совпадают ли типы данных столбцов и не могут ли имена столбцов отличаться (даже по регистру).
- Версии данных: Журнал транзакций для таблицы Delta содержит информацию о версиях, которая поддерживает эволюцию Delta Lake. Delta Lake отслеживает минимальную версию для чтения и записи отдельно.
- Путешествие во времени: Возможности Delta для путешествий во времени упрощают откат и аудит изменений данных. Каждая операция с дельта-таблицей или каталогом автоматически версионируется. Вы можете путешествовать во времени, используя отметку времени или номер версии.
 Перед записью из фрейма данных в таблицу Delta Lake проверяет, существуют ли столбцы в таблице во фрейме данных, совпадают ли типы данных столбцов и не могут ли имена столбцов отличаться (даже по регистру).
Перед записью из фрейма данных в таблицу Delta Lake проверяет, существуют ли столбцы в таблице во фрейме данных, совпадают ли типы данных столбцов и не могут ли имена столбцов отличаться (даже по регистру). Хватит читать! Давайте посмотрим, как Delta Lake работает на практике. производительность. Затем мы создаем дельта-таблицу, оптимизируем ее и запускаем второй запрос, используя дельта-версию той же таблицы Databricks, чтобы увидеть разницу в производительности. Мы также посмотрим на историю таблицы.
Мы также посмотрим на историю таблицы.
Используемый набор данных относится к полетам авиакомпаний в 2008 году. Он содержит более 7 миллионов записей. Я буду использовать Python для этого урока, но вы можете согласиться, поскольку API-интерфейсы примерно одинаковы для любого языка.
Мы прочитаем набор данных, который изначально имеет формат CSV:
рейсы = spark.read.format(“csv”) \
.option(“header”, “true”) \
.option(“ inferSchema», «true») \
.load(«/databricks-datasets/asa/airlines/2008.csv»)
Затем мы создадим таблицу из выборочных данных с помощью Parquet:
Flight.write.format(«parquet») \
.mode(«overwrite») \
.partitionBy(«Origin») \
. save(«/tmp/flights_parquet»)
Чтобы проверить производительность таблицы на основе паркета, мы запросим 20 крупнейших авиакомпаний с наибольшим количеством рейсов в 2008 г. по понедельникам по месяцам:
из pyspark.
Flight_parquet = spark.read.format («паркет») \
.load(«/tmp/flights_parquet»)
display(flights_parquet.filter(«DayOfWeek = 1») \
.groupBy(«Месяц», «Происхождение») \
.agg(count(«*» ).alias(«TotalFlights»)) \
.orderBy(«TotalFlights», по возрастанию = False) \
.limit(20))
 sql.functions import count
sql.functions import countЭтот запрос занял у меня около 38,94 секунды с кластером, использующим машину Standard_DS3_v2 тип; Память 14 ГБ с 4 ядрами, использующая 4–8 узлов.
Теперь попробуем Delta. Мы создадим таблицу на основе Delta, используя тот же набор данных:
Flights.write.format(«delta») \
.mode(«append») \
.partitionBy(«Origin») \
.save(«/tmp/flights_delta»)# Создать дельта-таблицу
display(spark.sql(«УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЮТ рейсы»))
display(spark.sql(«СОЗДАТЬ ТАБЛИЦУ Flights, ИСПОЛЬЗУЯ РАСПОЛОЖЕНИЕ DELTA ‘/tmp/flights_delta'»))
Перед тестированием таблицы Delta мы может оптимизировать его, используя ZORDER по столбцу DayofWeek . Этот столбец используется для фильтрации данных при запросе (выбор всех рейсов по понедельникам):
Этот столбец используется для фильтрации данных при запросе (выбор всех рейсов по понедельникам):
display(spark.sql(«ОПТИМИЗАЦИЯ рейсов ZORDER BY (DayofWeek)»))
Хорошо, теперь мы можем проверить производительность запроса при использовании Databricks Delta:
Flight_delta = spark.read \
.format («дельта») \
.load («/tmp/flights_delta»)display(
Flight_delta \
.filter («День недели = 1») \
.groupBy («Месяц», «Происхождение») \
.agg(count(«*») \
.alias(«TotalFlights»)) \
.orderBy(«TotalFlights», по возрастанию = False) \
.limit(20))
Выполнение запроса на Databricks Delta заняло всего 6,52 секунды. Это примерно в 5 раз быстрее!
Используя таблицу рейсов , мы можем просмотреть все изменения в этой таблице, выполнив следующее: 0 (нижняя строка) показывает исходную версию при создании таблицы. Строка версии 1 показывает, когда выполняется шаг оптимизации.
Ради интереса попробуем использовать таблицу рейсов версии 0, которая была до применения оптимизации на . Мы перечитаем данные таблицы версии 0 и запустим тот же запрос для проверки производительности:
Flight_delta_version_0 = spark.read \
.format(«delta») \
.option(«versionAsOf», » 0″) \
.load(«/tmp/flights_delta»)display(
Flight_delta_version_0.filter(«DayOfWeek = 1») \
.groupBy(«Month»,»Origin») \
.agg(count («*») \
.alias («TotalFlights»)) \
.orderBy(«TotalFlights», по возрастанию=False) \
.limit(20))
Запрос занял 36,3 секунды, используя тот же кластер, что и раньше. Это показывает, насколько важна оптимизация дельта-таблицы для производительности.
Надеюсь, эта статья поможет вам узнать о Databricks Delta! Если у вас есть какие-либо вопросы, вы можете оставить комментарий или написать мне по электронной почте: sameh.shar [at] gmail.
Источники :
- Глоссарий блоков данных — Delta Lake
- Apache Spark
- Databricks — Spark
- Databricks — Delta
- Databricks — учебник по оптимизации
- Databricks — Delta Lake Time Travel
Автор: Самех Шараф, инженер по данным, Ldt Co.
Первоначально опубликовано по адресу https://www.sertiscorp.com/
Построение дополнительных конвейеров данных с помощью Delta Lake | by Royal Cyber Inc.
Инженеров по данным часто просят переместить огромные куски организационных данных из источника данных в новое место назначения. Хотя это может показаться легкой работой, все усложняется, когда данные обновляются или поступают новые данные, и мы должны вливать их в одно и то же озеро данных. Предстоящая задача заключается в том, чтобы выяснить, какие файлы уже были переданы или обработаны, а какие — новые, которые необходимо переместить. В таких случаях очень полезными могут быть конвейеры данных, способные выполнять добавочную загрузку данных. И здесь такие изобретения, как Delta Lake, становятся актуальными для строительства таких трубопроводов. Давайте углубимся в эту тему.
Delta Lake — это уровень хранения, который находится поверх уровня данных и предоставляет расширенные функции, такие как свойство ACID. Он использует Apache Spark в качестве основного исполнительного механизма и значительно повышает производительность, масштабируемость и надежность озера данных. Озеро данных в обсуждении может быть предоставлено любым поставщиком облачных услуг, таким как AWS, Microsoft Azure и Google Cloud Platform.
Он использует Apache Spark в качестве основного исполнительного механизма и значительно повышает производительность, масштабируемость и надежность озера данных. Озеро данных в обсуждении может быть предоставлено любым поставщиком облачных услуг, таким как AWS, Microsoft Azure и Google Cloud Platform.
В традиционных базах данных отсутствуют встроенные регуляторные настройки, которые могут помочь специалистам по данным организовать свои данные так, как они предпочитают. Delta Lake от Databricks не только структурирует данные, но и позволяет пользователям создавать дополнительные конвейеры и использовать интеллектуальные функции.
В этом блоге мы познакомим вас с этапами создания инкрементного конвейера данных с использованием дельта-озера, что делает это возможным благодаря функции автозагрузки. Итак, давайте быстро рассмотрим некоторые основы, прежде чем мы начнем создавать конвейер.
Автозагрузчик позволяет поэтапно перемещать данные, поддерживая очередь в невыполненной работе. Это помогает озеру дельты определить, сколько и какие данные обрабатываются. Эта функция в конечном итоге позволяет озеру различать существующие данные и новые входящие файлы, которые необходимо обработать.
Это помогает озеру дельты определить, сколько и какие данные обрабатываются. Эта функция в конечном итоге позволяет озеру различать существующие данные и новые входящие файлы, которые необходимо обработать.
Функция автозагрузчика напоминает функцию просмотра файлов, которая обычно используется в AWS. Наблюдатель за файлами постоянно отслеживает каталог пользователя и генерирует уведомления, если появляются новые файлы. Автозагрузчик работает по тому же принципу — автоматически определяет новые поступления и обработанные файлы. Можно определить изменения, сравнив исходные данные и данные, лежащие в месте назначения.
Когда мы имеем дело с добавочными конвейерами данных, становится сложно выполнять всю обработку и преобразования на одном ноутбуке. Чтобы эффективно выполнять работу, нам часто приходится создавать более мелкие задачи (которые могут быть записной книжкой Python или библиотекой Java) и объединять их для создания целого конвейера данных.
В Databricks за каждой задачей следует следующая задача, которая показывает зависимость. Вам не нужны сторонние платформы, такие как Airflow, для выполнения задачи. Databricks — это унифицированное решение, позволяющее организовать весь конвейер в рамках собственной системы. Вы можете создавать эти задачи с помощью таких инструментов, как CLI и язык программирования Python.
Теперь давайте перейдем к реализации и создадим архитектуру конвейера в Databricks.
Начнем с загрузки данных в Bronze Table. Он содержит необработанные данные, полученные из различных источников. Сбор данных, как показано ниже, представляет собой записную книжку бронзового уровня. Это должно быть нашей отправной точкой; нам просто нужно извлечь данные и сохранить их в какой-нибудь целевой таблице.
Ниже облачные файлы представляют собой автозагрузчик в модулях данных. Добавив эти строки, вы можете активировать механизм Spark, чтобы использовать автозагрузчик для обнаружения новых файлов и обработки только тех, которые еще не были обработаны.
Вы также можете увидеть предварительную обработку на изображении выше. Например, «разделитель» указывает, что некоторые файлы (например, файлы, разделенные табуляцией) необходимо прочитать, а «многострочный» показывает, что наш CSV-файл содержит некоторые столбцы, содержащие данные более чем в двух или трех строках.
Например, «разделитель» указывает, что некоторые файлы (например, файлы, разделенные табуляцией) необходимо прочитать, а «многострочный» показывает, что наш CSV-файл содержит некоторые столбцы, содержащие данные более чем в двух или трех строках.
Наш путь в этом конкретном случае присутствует в озере данных Azure, а наш дельта-каталог YouTube содержит две папки.
Папка data содержит видеоданные в формате CSV.
Формат «метаданные» содержит данные в формате JSON. Это необработанные данные, которые будут обработаны и уточнены серебряным блокнотом.
Нам нужно установить флаг триггера, когда мы планируем читать данные триггерным способом. Его противоположностью является непрерывный флаг, который означает, что ваш ноутбук будет продолжать работать, пока вы не остановите его вручную. Установив параметр «trigger( availableNow = True)», вы указываете своей записной книжке Databricks извлекать все данные, которые еще не обработаны, обрабатывать их и автоматически отключаться после выполнения задачи.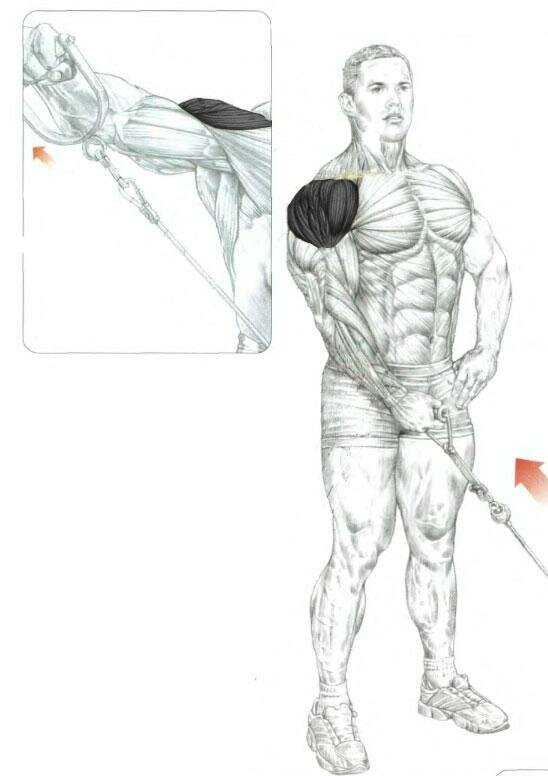
«Расположение контрольной точки», как показано ниже, помогает пользователям определить объем данных, которые были обработаны, и какие данные необходимо обработать. Опция «mergeSchema» предназначена для того, чтобы убедиться, что можно обрабатывать разные схемы, поскольку вы не уверены в том, какие схемы содержат ваши необработанные данные и как они могут меняться со временем.
Более того, мы использовали здесь внешние таблицы данных, как указано путем, потому что даже если вы случайно удалите данные во внешних таблицах, связанные данные, относящиеся к удаленной таблице, не будут потеряны.
Все вышеуказанные шаги повторяются и для метаданных; единственная разница в том, что мы указали формат файла JSON, а не CSV.
При работе со слоем серебра необходимо сначала очистить данные. За ним следует процесс преобразования, который удаляет нулевые значения и стандартизирует данные. Кроме того, если вы планируете создать и запустить конвейер позже, вам пока не нужно запускать записную книжку, связанную с data_bronze.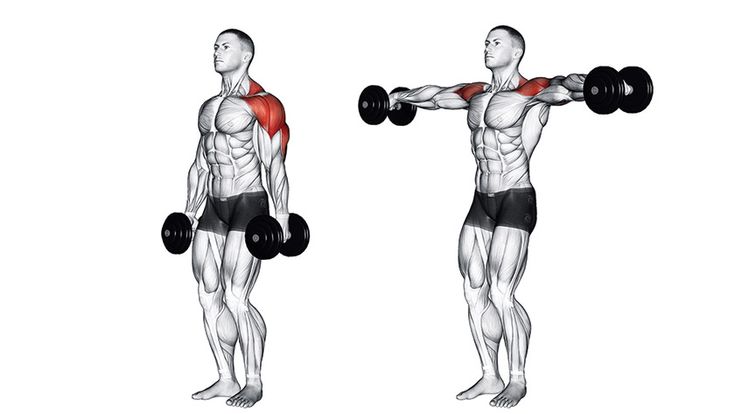
Тем не менее, мы запустили блокнот на изображении ниже для демонстрации схемы.
Как вы могли заметить, наша схема не соответствует формату, необходимому для бизнеса. Например, часть, которая говорит «trending_date», должна фактически отображать формат даты, а не фразу как есть.
Следующий код преобразует наши неструктурированные данные в структурированную форму. Мы внедрили схему, преобразовав ее в надлежащий формат в соответствии с требованиями бизнеса.
Мы указали функции pyspark как F. Посмотрите на изображение ниже.
Таким же образом мы также проанализировали формат файлов данных метаданных — ранее представленный во вложенной форме.
Вот как мы это проанализировали.
Мы создаем только временные виды. Это так, потому что это всего лишь промежуточный шаг. Если вы зарегистрируете таблицу и не поместите ее в качестве временного представления, это повлечет за собой дополнительные расходы на уровне хранилища.
В качестве последнего шага мы объединяем чистые данные и таблицы метаданных.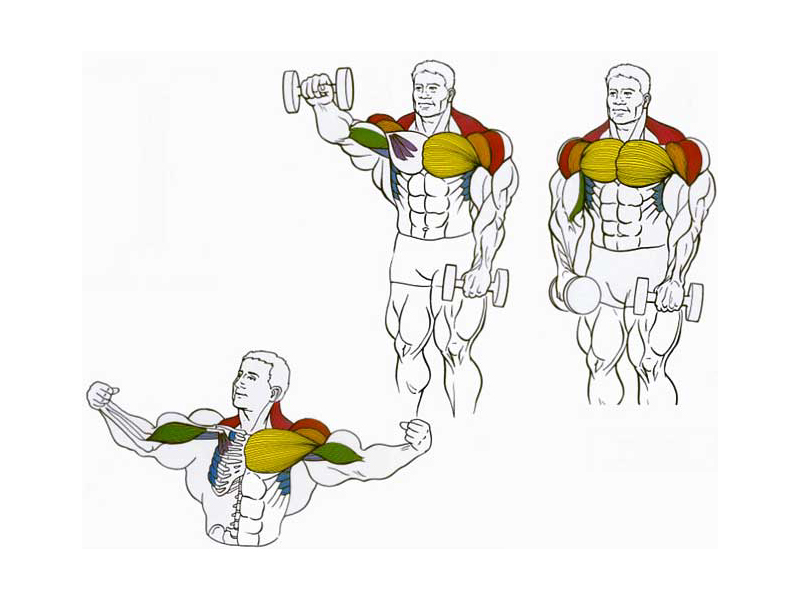
После объединения двух мы сохраним данные в следующей таблице. Его можно легко использовать позже. Термин «writeStream» означает, что мы планируем запускать наш конвейер в потоковом режиме, то есть мы планируем постепенно обновлять новые данные и объединять их с уже обработанными данными за один раз.
Ниже мы собираем данные для преобразования золота, считывая данные из слоя серебра и применяя groupBy. Мы группируем данные в соответствии с кодом страны для создания статистики по конкретной стране.
То же самое делается для другой категории, т.е. Категории популярных видео. Кроме того, во время агрегации мы регистрируем таблицу в метахранилище блоков данных и создаем внешнюю таблицу для производственных целей.
Вы можете увидеть созданный конвейер ниже. Чтобы создать свою собственную, вам просто нужно щелкнуть опцию «вакансии», указанную в верхней правой части экрана, и нажать «создать вакансию».
Теперь назовите свою задачу, опишите тип (в данном случае ноутбук) и укажите путь к блокноту. Вы можете использовать существующий кластер или создать новый, в этом случае; вам, возможно, придется платить за используемый ресурс на основе потребления/использования в секунду. Вы также можете установить определенные параметры в вашем конвейере, например, метку времени.
Вы можете использовать существующий кластер или создать новый, в этом случае; вам, возможно, придется платить за используемый ресурс на основе потребления/использования в секунду. Вы также можете установить определенные параметры в вашем конвейере, например, метку времени.
Это поток наших данных — проходящий через бронзовую, серебряную и золотую стадии соответственно.
Оценим результаты. Как вы можете видеть ниже, мы обработали данные, относящиеся к трем странам. Теперь мы получим новые данные и снова запустим конвейер.
Для этого нам нужно вручную загрузить файл CSV и метаданные. После загрузки новых данных Databricks идентифицирует новые данные с помощью Auto Loader.
Мы можем либо запустить конвейер вручную, либо запланировать его на определенную дату и момент времени.
На данный момент мы запустили конвейер вручную. Вы можете увидеть выполнение задания на изображении ниже. Если вы нажмете на задание, оно даст вам подробную информацию о том, какая ячейка работает, а какая завершена.
После бронзового этапа начнется серебряный. Вы также можете увидеть подробности запуска для него. Вы также можете щелкнуть дальше, чтобы увидеть, какой запрос выполняется в конкретном случае. Серебряный этап может занять некоторое время, так как он объединяет данные из двух разных источников.
Финальная тетрадь действует после серебряной стадии. Здесь начинают работать агрегированные данные. Вы можете увидеть продолжительность в левой части изображения. Зеленая галочка появляется слева как статус после успешного выполнения задания.
Когда вы снова запустите таблицу, вы заметите, что ранее у нас не было данных, связанных с GBR. Автозагрузчик автоматически обнаружил новые данные и объединил их с уже обработанными данными, никоим образом не загрязняя их.
Этот последний шаг завершает нашу задачу.
В этом блоге мы обсудили создание добавочных конвейеров данных с помощью Delta Lake от Databricks. Если у вас есть какие-либо вопросы относительно процесса и платформы, команда разработчиков данных и науки о данных Royal Cyber может помочь вам с ними.