Форум качков натуралов: Качки не вдохновляют ? — 125 ответов на форуме Woman.ru
«В натураху». Каких результатов ждать от тренинга без стероидов
Натуральный силовой тренинг сделает вас сильнее, мускулистее и лучше. Однако вряд ли он принесет вам мышцы профессионального культуриста с фотографии – если только у вас нет особой генетической предрасположенности к бодибилдингу.
Каких реальных результатов ждать от тренинга без стероидов и почему «в натураху» нельзя накачать бицепсы в 50 сантиметров. Разбирался «Советский спорт Life&Style».
Вместе с мышцами вырастет лишний вес
Cтатьи | Кто такие дрищи? Отвечают бодибилдеры
Натуральные силовые тренировки способны дать большой прирост массы тела. Программа для новичков, основанная на базовых упражнениях, дает в среднем прибавку от 8 до 13 кг в первый год тренировок. В следующий год – еще 3-4 кг. На третий год – 1-2 кг (далее прогресс замедляется и за каждый грамм массы придется вести напряженную борьбу).
При этом будьте готовы: организм, который работает в анаболическом режиме роста, будет набирать вместе с мускулами и «грязный вес» – жировые отложения. Вы можете стать большим и массивным, но при этом почти наверняка забудете как выглядит ваш пресс. Это обратная сторона натурального тренинга.
Вы можете стать большим и массивным, но при этом почти наверняка забудете как выглядит ваш пресс. Это обратная сторона натурального тренинга.
Что делать: сократить набор «грязного веса» можно подсчетом калорий, диетой, бегом, включением «жиросжигающих» интенсивных тренировок. Набор мышечной массы из-за этого будет происходить медленнее – и, скорее всего, вместе с мускулами вы все же прибавите немного жира.
Накачать руки в 50 сантиметров – не удастся
Шварценеггер на пике формы хвастался руками объемом в 53 сантиметров. Фил Хит, сегодняшний обладатель титула «Мистер Олимпия», имеет руки в 56 сантиметров. Такие объемы недостижимы при натуральном тренинге.
Доктор Рэндал Штроссен, специалист по силовому тренингу и автор методики «Суперприседания», полагает: максимальный объем руки, которого может добиться натуральный атлет, в среднем составляет 40-43 сантиметра.
Что делать: тренируйте руки не чаще двух раз в неделю (многим хватит и одного раза) – чтобы сохранить силы для роста больших мышечных групп спины и ног, которые составят основу вашей массы. В тренировке рук больше внимания уделяйте трицепсу. Именно он, а не бицепс, создает основной объем руки.
В тренировке рук больше внимания уделяйте трицепсу. Именно он, а не бицепс, создает основной объем руки.
Круглые плечи – почти всегда результат стероидов
Натуральный тренинг тоже поможет «вырастить» дельты и рельефно прорисовать их заднюю, среднюю и переднюю части. Однако, если вы «чистый» атлет с обычной генетикой, ваши плечи хоть и приобретут массивность, но останутся покатыми. Круглые плечи, похожие на шары, у профессиональных бодибилдеров – почти всегда результат употребления анаболических стероидов.
Что делать: добавьте к тренировке плеч упражнение «шраги» – подъем плеч, стоя с тяжелой штангой или гантелями в опущенных руках. Это движение хорошо развивает трапеции – мышцы, которые идут от плеча к шее. Развитые трапеции компенсируют недостаток округлости плеч и дадут визуальный эффект атлетичной фигуры.
Вы будете долго и болезненно восстанавливаться
Cтатьи | Что чаще всего убивает культуристов. Стероиды, препараты для сушки, валиум
В среднем от трех до пяти дней занимает восстановление после серии тяжелых приседаний. А приседать с прогрессией весов вам придется: эксперты считают присед самым эффективным упражнением для наборам массы натуральными атлетами.
А приседать с прогрессией весов вам придется: эксперты считают присед самым эффективным упражнением для наборам массы натуральными атлетами.
Проблемы начинаются на второй день после тренинга ног – вы замечаете, что вам трудно вставать и садиться. На третий день проблемы вызывает любой спуск и подъем по лестнице. На четвертый вам все еще больно. И только к пятому дню вы чувствуете облегчение. По графику уже пора снова идти делать приседания. Это значит, что все начнется заново.
Что делать: боли в ногах не избежать, если вы нацелены набирать массу натурально. Частично пост-тренировочные болевые симптомы снимает заминка – комплекс упражнений на расслабление и растягивание. Другая рекомендация: выполнять легкие серии приседаний с собственным весом в дни боли. Это поможет мышцам избавиться от молочной кислоты, главного источника болевых ощущений.
Рано или поздно произойдет застой в рабочих весах
Прогрессия нагрузок – один из главных принципов эффективного натурального тренинга. Мышцу нужно «удивлять». Иначе она быстро привыкнет к тренингу и перестанет расти.
Мышцу нужно «удивлять». Иначе она быстро привыкнет к тренингу и перестанет расти.
Самый простой способ увеличения нагрузок – добавить вес на штангу. Но рано или поздно (обычно в течение 3-4 лет тренинга) вы достигнете своего генетического максимума: присесть или пожать больший вес не позволят природные ограничения организма.
Что делать: пробовать увеличить интенсивность тренинга другими путями – сокращением времени на отдых, большим количеством повторов, объединением упражнений в супер-сеты.
Что еще нужно знать «натуральному» атлету:
– методики, которые предлагают оставлять в программе только «базу» – присед, тягу и жим, нужно использовать осторожно. Этот тренинг действительно сделает вас более массивным. Но без отсутствия изолирующих и кардиоупражнений, вы станете похожим на коренастого толстяка.
– тягу в наклоне лучше исключить. Тяга в наклоне – отличное «массонаборное упражанение для спины. Но оно же прирастит вам несколько сантиметров в боках за счет воздействия на мышцы кора. Талия будет визуально казаться толще. Если ваша цель – эстетичная фигура откажитесь от этого упражнения.
Талия будет визуально казаться толще. Если ваша цель – эстетичная фигура откажитесь от этого упражнения.
– откажитесь от силовых рекордов в становой тяге. Становая тяга – потенциально травмоопасное упражнение, которое способно поставить крест на силовых тренировках. Откажитесь от «проходок» к максимальному весу в становой тяге. Делайте ее в количестве не менее 6 повторов. При болях и неудобствах в пояснице исключайте становую тягу из своей программы.
– режим 5Х5 растит силу, но не размер мышц. Режим тренинга 5Х5 (пять подходов – пять повторов), который часто используют натуральные атлеты-новички, в первую очередь направлен на развитие силы. Если ваша цель – максимальная гипертрофия мышц, используйте программы с числом повторов от 8 в подходе.
Редакция «Советский спорт Life&Style» выступает за натуральный тренинг без применения средств фармакологии.
источник: «Советский спорт»
Моделирование языка и двунаправленные представления кодировщиков: обзор ключевых технологий | Качков
1. Cho K., Merriënboer B. van, Gulcehre C., Bahdanau D., Bougares F., Schwenk H., Bengio Y. Learning phrase representations using RNN encoder-decoderfor statistical machine translation. Proceedings of the 2014. Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014, pp. 1724–1734. https://doi.org/10.3115/v1/D14-1179
Cho K., Merriënboer B. van, Gulcehre C., Bahdanau D., Bougares F., Schwenk H., Bengio Y. Learning phrase representations using RNN encoder-decoderfor statistical machine translation. Proceedings of the 2014. Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014, pp. 1724–1734. https://doi.org/10.3115/v1/D14-1179
2. Sutskever I. Sequence to Sequence Learning with Neural Networks / I. Sutskever, O. Vinyals, Q. V. Le // Advances in Neural Information Processing Systems. — 2014. — P. 3104–3112. ArXiv preprint: https://arxiv.org/abs/1409.3215
3. Serban I. V., Lowe R., Charlin L., Pineau J. Generative deep neural networks for dialogue: A short review. Neural Information Processing Systems, Workshop on Learning Methods for Dialogue, 2016. Available at: https://arxiv.org/abs/1611.06216 (accessed 07.07.2020).
4. Vinyals O. Show and tell: A neural image caption generator / O. Vinyals, A. Toshev, S. Bengio, D. Erhan // Proceedings of the IEEE conference on computer vision and pattern recognition. — 2015. — P. 3156–3164. https://doi.org/10.1109/CVPR.2015.7298935
— 2015. — P. 3156–3164. https://doi.org/10.1109/CVPR.2015.7298935
5. Loyola P. A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes / P. Loyola., E. Marrese-Taylor, Y. Matsuo // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. — 2017. — Vol. 2. — P. 287-292. https://doi.org/10.18653/v1/P17-2045
6. Lebret R. Neural Text Generation from Structured Data with Application to the Biography Domain / R. Lebret., D. Grangier, M. Auli // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. — 2016. — P. 1203–1213. https://doi.org/10.18653/v1/D16-1128
7. Николенко С., Кандурин А., Архангельская Е. Глубокое обучение. — Санкт-Петербург: Питер, 2020. — 480 с.
8. Bahdanau D. Neural Machine Translation by Jointly Learning to Align and Translate / D. Bahdanau, K. Cho, Y. Bengio // International Conference on Learning Representations. — 2015. ArXiv preprint: https://arxiv. org/abs/1409.0473
org/abs/1409.0473
9. Schuster M. Bidirectional recurrent neural networks / M. Schuster, K. K. Paliwal // Signal Processing, IEEE Transactions on 45.11. — 1997. — P. 2673-2681. https://doi.org/10.1109/78.650093
10. Luong T. Effective Approaches to Attention-based Neural Machine Translation / T. Luong, H. Pham, C. D. Manning // Proceedings of EMNLP 2015: Conference on Empirical Methods in Natural Language Processing. — 2015. — P. 1412-1421. https://doi.org/10.18653/v1/D15-1166
11. Chung J. A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation / J. Chung, K. Cho, Y. Bengio // Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. — 2016. — Vol. 1. — P. 1693–1703. https://doi.org/10.18653/v1/P16-1160
12. Rush A. A Neural Attention Model for Abstractive Sentence Summarization / A. Rush, S. Chorpa, J. Weston // Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. — 2015. — P. 379–389. https://doi.org/10.18653/v1/D15-1044
— P. 379–389. https://doi.org/10.18653/v1/D15-1044
13. Attention-Based Models for Speech Recognition / J. Chorowski [et al.] // Proceedings of the 28th International Conference on Neural Information Processing Systems. — 2015. — Vol. 1. — P. 577–585. ArXiv preprint: https://arxiv.org/abs/1506.07503
14. Chan W. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition / W. Chan, N. Jaitly, Q. V. Le, O. Vinyals // 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). — 2016. — P. 4960-4964. https://doi.org/10.1109/ICASSP.2016.7472621
15. Teaching Machines to Read and Comprehend / K. M. Hermann [et al.] // Advances in Neural Information Processing Systems 28: 29th Annual Conference on Neural Information Processing Systems 2015. — 2015. — P. 1693-1701. ArXiv preprint: https://arxiv.org/abs/1506.03340
16. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation / Y. Wu [et al.] // ArXiv preprint. — 2016. https://arxiv.org/abs/1609.08144
Wu [et al.] // ArXiv preprint. — 2016. https://arxiv.org/abs/1609.08144
17. Hochreiter S. Long short-term memory / S. Hochreiter, J. Schmidhuber // Neural Computation. — 1997. — Vol. 9 (8). — P. 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
18. Cho K. On the properties of neural machinetranslation: Encoder-decoder approaches / K. Cho, B. van Merrienboer, D. Bahdanau, Y. Bengio // Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation — 2014. — P. 103–111. https://doi.org/10.3115/v1/W14-4012
19. Martin E., Cundy C. Parallelizing Linear Recurrent Neural Nets Over Sequence Length // International Conference on Learning Representations. — 2018. ArXiv preprint:https://arxiv.org/abs/1709.04057
20. Neural machine translation in linear time / N. Kalchbrenner [et al.] // ArXiv preprint. — 2016. https://arxiv.org/abs/1610.10099.
21. Convolutional sequence to sequence learning / J. Gehring [et al.] // Proceedings of the 34th International Conference on Machine Learning — 2017. — Vol. 70. — P. 1243–1252. ArXiv preprint: https://arxiv.org/abs/1705.03122
— Vol. 70. — P. 1243–1252. ArXiv preprint: https://arxiv.org/abs/1705.03122
22. LeCun Y. Gradient-based learning applied to document recognition / Y. LeCun, L. Bottou, Y. Bengio, P. Haffner // Proceedings of the IEEE. — 1998. — Vol. 86 (11). — P. 2278–2324. https://doi.org/10.1109/5.726791
23. Parikh A. P. A Decomposable Attention Model for Natural Language Inference / A. P. Parikh, O. Täckström, D. Das, J. Uszkoreit // Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. — 2016. — P. 2249–2255. https://doi.org/10.18653/v1/D16-1244
24. Attention Is All You Need / A. Vaswani [et al.] // Publication: NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems. — 2017. — P. 6000–6010. ArXiv preprint: https://arxiv.org/abs/1706.03762
25. Mitkov R. Anaphora Resolution: The State of the Art. / R. Mitkov // Paper based on the COLING’98/ACL’98 tutorial on anaphora resolution. — University of Wolverhampton..jpg) — 1999.
— 1999.
26. Ba J. L. Layer normalization / J. L. Ba, J. R. Kiros, G. E. Hinton // ArXiv preprint. — 2016. https://arxiv.org/abs/1607.06450.
27. Neural Speech Synthesis with Transformer Network / N. Li [et al.] // The AAAI Conference on Artificial Intelligence (AAAI). — 2019. ArXiv preprint: https://arxiv.org/abs/1809.08895
28. Khandelwal U. Sample Efficient Text Summarization Using a Single Pre-Trained Transformer / U. Khandelwal, K. Clark, D. Jurafsky, Ł. Kaiser. // ArXiv preprint. — 2019. https://arxiv.org/abs/1905.08836
29. Vlasov V. Dialogue Transformers / V. Vlasov, J. E. M. Mosig, A. Nicho // ArXiv preprint. — 2019. https://arxiv.org/abs/1910.00486
30. Griffith K. Solving Arithmetic Word Problems Automatically Using Transformer and Unambiguous Representations / K. Griffith and J. Kalita // 2019 International Conference on Computational Science and Computational Intelligence (CSCI). — 2019. — P. 526-532. https://doi.org/10.1109/CSCI49370.2019.00101
31. Kang W. Self-Attentive Sequential Recommendation / W. Kang, J. McAuley // 2018 IEEE International Conference on Data Mining (ICDM). — 2018. — P. 197-206.https://doi.org/10.1109/ICDM.2018.00035.
Kang W. Self-Attentive Sequential Recommendation / W. Kang, J. McAuley // 2018 IEEE International Conference on Data Mining (ICDM). — 2018. — P. 197-206.https://doi.org/10.1109/ICDM.2018.00035.
32. Music Transformer / C.-Z. A. Huang [et al.] // ArXiv preprint. — 2018. https://arxiv.org/abs/1809.04281.
33. Universal Transformers / M. Dehghani [et al.] // 7th International Conference on Learning Representations. — 2019. ArXiv preprint: https://arxiv.org/abs/1807.03819.
34. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context / Z. Dai [et al.] // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. — 2019. — P. 2978–2988. https://doi.org/10.18653/v1/P19-1285
35. So D. R. The Evolved Transformer / D. R. So, C. Liang, Q. V. Le // Proceedings of the 36th International Conference on Machine Learning. — 2019. — P. 5877-5886. ArXiv preprint: https://arxiv.org/abs/1901.11117
36. Transformer-XH: Multi-Evidence Reasoning with eXtra Hop Attention / C.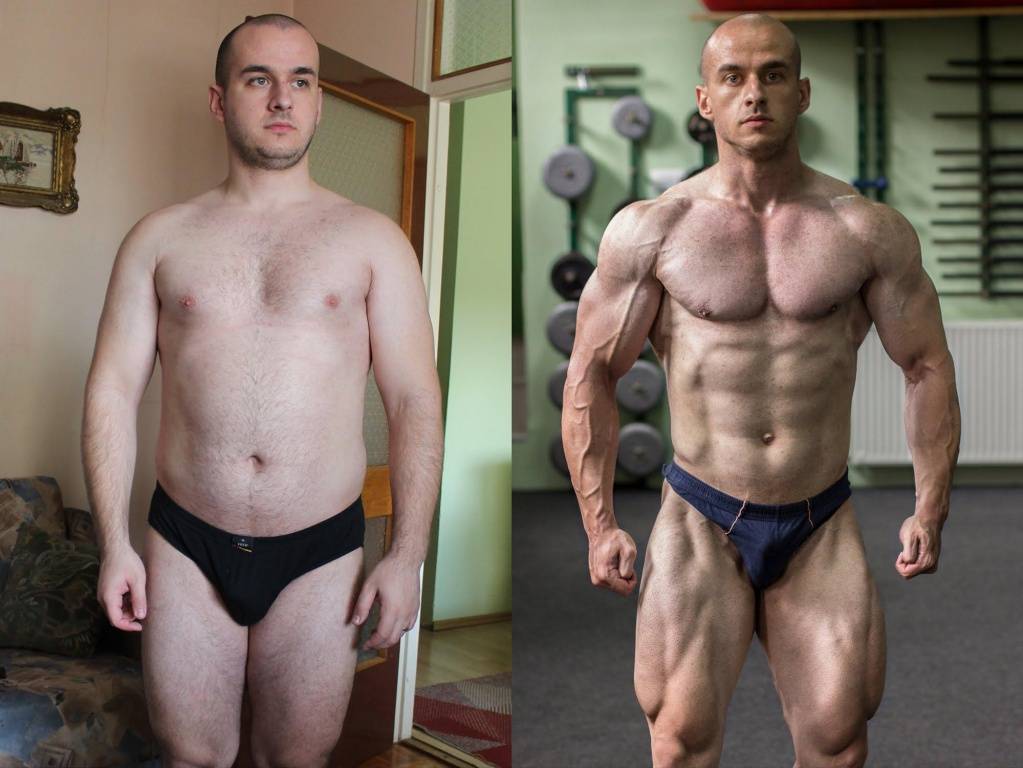 Zhao [et al.] // 8th International Conference on Learning Representations. — 2020. Available at: https://openreview.net/forum?id=r1eIiCNYwS (Accessed 10 July 2020)
Zhao [et al.] // 8th International Conference on Learning Representations. — 2020. Available at: https://openreview.net/forum?id=r1eIiCNYwS (Accessed 10 July 2020)
37. Mikolov T. Distributed Representations of Words and Phrases and their Compositionality / T. Mikolov, K. Chen, G. Corrado, J. Dean // Proceedings of the 26th International Conference on Neural Information Processing Systems. — 2013. — Vol. 2. — P. 3111–3119. ArXiv preprint: https://arxiv.org/abs/1310.4546
38. Pennington J. Glove: Global Vectors for Word Representation / J. Pennington, R. Socher, C. D. Manning // Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. — 2014. — P. 1532–1543. https://doi.org/10.3115/v1/D14-1162
39. Sahlgren M. The Distributional Hypothesis. From context to meaning / M. Sahlgren // Distributional models of the lexicon in linguistics and cognitive science (Special issue of the Italian Journal of Linguistics), Rivista di Linguistica. — Vol. 20 (1). — 2008. — P. 33—53.
— 2008. — P. 33—53.
40. B. McCann. Learned in Translation: Contextualized Word Vectors / B. McCann, J. Bradbury, C. Xiong, R. Socher // 31st Conference on Neural Information Processing Systems, Long Beach. — 2017. — P. 6297–6308. ArXiv preprint: https://arxiv.org/abs/1708.00107
41. Hedderich M. A. Using Multi-Sense Vector Embeddings for Reverse Dictionaries / M. A. Hedderich, A. Yates, D. Klakow, G. de Melo // Proceedings of the 13th International Conference on Computational Semantics — Long Papers. — 2019. — P. 247–258. https://doi.org/10.18653/v1/W19-0421
42. Ruder S. Neural Transfer Learning for Natural Language Processing / S. Ruder // Ph.D. thesis, National University of Ireland, Galway. — 2019.
43. ImageNet: A large-scale hierarchical image database / J. Deng [et al.] // IEEE Conference on Computer Vision and Pattern Recognition. — 2009. — P. 248–255. https://doi.org/10.1109/CVPR.2009.5206848
44. Towards Accurate Multi-person Pose Estimation in the Wild / G. Papandreou [et al.] // IEEE Conference on Computer Vision and Pattern Recognition. — 2017. — P. 3711-3719. https://doi.org/10.1109/CVPR.2017.395
Papandreou [et al.] // IEEE Conference on Computer Vision and Pattern Recognition. — 2017. — P. 3711-3719. https://doi.org/10.1109/CVPR.2017.395
45. He K. Mask R-CNN / K. He, G. Gkioxari, P. Dollár, R. Girshick // IEEE International Conference on Computer Vision. — 2017. — P. 2980-2988. https://doi.org/10.1109/ICCV.2017.322
46. Exploring the Limits of Weakly Supervised Pretraining / D. Mahajan [et al.] // European Conference on Computer Vision. — 2018. — P. 181–196 https://doi.org/10.1007/978-3-030-01216-8_12
47. Dai A. M. Semi-supervised Sequence Learning / A. M. Dai, Q. V. Le // Proceedings of the 28th International Conference on Neural Information Processing Systems. — 2015. — Vol. 2. — P. 3079–3087. https://doi.org/10.18653/v1/P17-1161
48. Peters M. E. Semi-supervised sequence tagging with bidirectional language models / M. E. Peters, W. Ammar, C. Bhagavatula, R. Power // Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. — 2017. — Vol. 1. — P. 1756-1765. ArXiv preprint: https://arxiv.org/abs/1705.00108
— 2017. — Vol. 1. — P. 1756-1765. ArXiv preprint: https://arxiv.org/abs/1705.00108
49. Howard J. Universal Language Model Fine-tuning for Text Classification / J. Howard, S. Ruder // Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. — 2018. — Vol. 1. — P. 328–339. https://doi.org/10.18653/v1/P18-1031
50. Deep contextualized word representations / M. E. Peters [et al.] // Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. — 2018. — Vol. 1. — P. 2227–2237. https://doi.org/10.18653/v1/N18-1202
51. Merity S. Pointer Sentinel Mixture Models / S. Merity, C. Xiong, J. Bradbury, R. Socher // 5th International Conference on Learning Representations. — 2017. ArXiv preprint: https://arxiv.org/abs/1609.07843
52. Radford A. Improving language understanding with unsupervised learning / A. Radford, K. Narasimhan, T. Salimans, I. Sutskever // Technical report, OpenAI. — 2018. Available at: https://openai.com/blog/language-unsupervised/ (Accessed 10 July 2020)
— 2018. Available at: https://openai.com/blog/language-unsupervised/ (Accessed 10 July 2020)
53. Generating Wikipedia by Summarizing Long Sequences / P. J. Liu [et al.] // 6th International Conference on Learning Representations. — 2018. ArXiv preprint: https://arxiv.org/abs/1801.10198
54. Devlin J. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding / J. Devlin, M.-W. Chang, K. Lee, K. Toutanova // Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. — 2019. — Vol. 1. — P. 4171–4186. https://doi.org/10.18653/v1/N19-1423
55. Taylor W. L. Cloze procedure: A new tool for measuring readability / W. L. Taylor // Journalism Bulletin. — 1953. — Vol. 30(4) — P. 415–433.
56. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books / Y. Zhu [et al.] // Proceedings of the IEEE international conference on computer vision. — 2015. — P. 19–27. https://doi.org/10.1109/ICCV.2015.11
— 2015. — P. 19–27. https://doi.org/10.1109/ICCV.2015.11
57. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding / A. Wang [et al.] // Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. — 2018. — P. 353–355. https://doi.org/10.18653/v1/W18-5446
58. RoBERTa: A Robustly Optimized BERT Pretraining Approach / Y. Liu [et al.] // ArXiv preprint. — 2019. https://arxiv.org/abs/1907.11692
59. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations / Z. Lan [et al.] // 8th International Conference on Learning Representations. — 2020. Available at: https://openreview.net/forum?id=h2eA7AEtvS (Accessed 10 July 2020)
60. Sanh V. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter / V. Sanh, L. Debut, J. Chaumond, T. Wolf // Conference on Neural Information Processing Systems. — 2019. ArXiv preprint: https://arxiv.org/abs/1910.01108.
61. Hinton G. Distilling the Knowledge in a Neural Network / G. Hinton, O. Vinyals, J. Dean // Neural Information Processing Systems. Deep Learning and Representation Learning Workshop. — 2015. ArXiv preprint: https://arxiv.org/abs/1503.02531
Distilling the Knowledge in a Neural Network / G. Hinton, O. Vinyals, J. Dean // Neural Information Processing Systems. Deep Learning and Representation Learning Workshop. — 2015. ArXiv preprint: https://arxiv.org/abs/1503.02531
62. TinyBERT: Distilling BERT for Natural Language Understanding / X. Jiao [et al.] // ArXiv preprint. — 2019. https://arxiv.org/abs/1909.10351
63. Liu. X. Multi-Task Deep Neural Networks for Natural Language Understanding / X. Liu, P. He, W. Chen, J. Gao // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. — 2019. — P. 4487–4496. https://doi.org/10.18653/v1/P19-1441
64. Representation learning using multi-task deep neural networks for semantic classification and information retrieval / X. Liu [et al.] // Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. — 2015. — P. 912–921. https://doi.org/10.3115/v1/N15-1092
65. StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding / W. Wang [et al.] // 8th International Conference on Learning Representations. — 2020. Available at: https://openreview.net/forum?id=BJgQ4lSFPH (Accessed 10 July 2020)
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding / W. Wang [et al.] // 8th International Conference on Learning Representations. — 2020. Available at: https://openreview.net/forum?id=BJgQ4lSFPH (Accessed 10 July 2020)
66. Elman J. L. Finding structure in time / Elman J. L. // Cognitive science. — 1990. — Vol. 14 (2). — P. 179–211.
67. BioBERT: a pre-trained biomedical language representation model for biomedical text mining / J. Lee [et al.] // Bioinformatics. — 2020. — Volume 36 (4). — P. 1234–1240. https://doi.org/10.1093/bioinformatics/btz682
68. Lu J. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks / J. Lu, D. Batra, D. Parikh, S. Lee // ArXiv preprint. — 2019. https://arxiv.org/abs/1908.02265
69. Niven T. Probing Neural Network Comprehension of Natural Language Arguments / T. Niven, H.-Y. Kao // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. — 2019. — P. 4658–4664. https://doi.org/10.18653/v1/P19-1459
— 2019. — P. 4658–4664. https://doi.org/10.18653/v1/P19-1459
70. HellaSwag: Can a Machine Really Finish Your Sentence? / R. Zellers [et al.] // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. — 2019. — P. 4791–4800. https://doi.org/10.18653/v1/P19-1472
71. McCoy T. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference / T. McCoy, E. Pavlick, T. Linzen // Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. — 2019. — P. 3428–3448. https://doi.org/10.18653/v1/P19-1334
Миру нужно больше натуралов
JavaScript отключен. Для лучшего опыта, пожалуйста, включите JavaScript в вашем браузере, прежде чем продолжить.
-
Автор темы
ловай -
Дата начала
Ловай
Все дело в Маосе
#1
Один лайнер заходит далеко. Для настоящего смеха нужен кто-то, кто подготовит кульминацию. Некоторые из них непреднамеренно натуралы. Большинство просто стараются на славу сами. Я так же виновен в этом, как и все остальные.
Был бы Лу Костелло смешным без Бада Эббота?
Обычный парень говорит: «Привет, как дела?» На что в ответ: «Все в порядке, спасибо».
Натурал спрашивает: «Эй! Как дела?» давая респонденту возможность ответить что-то вроде: «Он висит, как испуганная черепаха. Спасибо, что спросили».
Минте
Мне нужен быстрый заголовок
#2
Я почти забыл, что было время, когда натурал означал кого-то вроде Эда МакМэхона.
Фил47ук
Старший член
#3
Re…. «Миру нужно больше натуралов».
Слишком верно, слишком верно..
Пейджинг Васко… Пейджинг Васко….
.
Ловай
Все дело в Маосе
#4
Часто, когда я вижу пост здесь, я хочу сказать что-то, что автор может счесть оскорбительным, поэтому я сдерживаюсь, но на самом деле мой пост предназначен для создания комедийного золота.
Ага… Где Васко!
снимок
Старший член
#5
шлепок сказал:
эй lǎowài угадай, кто спрашивал о тебе вчера!
Нажмите, чтобы развернуть…
лǎовай; сказал:
о да кто???!
Нажмите, чтобы развернуть.
..
 ..
..шлепок сказал:
Как обычно никого не ебет…
Нажмите, чтобы развернуть…
НРБК
Старший член
#6
lǎowài;6332888 сказал:
До сих пор идут только одни вкладыши. Для настоящего смеха нужен кто-то, кто подготовит кульминацию. Некоторые из них непреднамеренно натуралы. Большинство просто стараются на славу сами. Я так же виновен в этом, как и все остальные.
Был бы Лу Костелло смешным без Бада Эббота?
Обычный парень говорит: «Привет, как дела?» На что в ответ: «Все в порядке, спасибо».
Натурал спрашивает: «Эй! Как дела?» давая респонденту возможность ответить что-то вроде: «Он висит, как испуганная черепаха. Спасибо, что спросили».
Нажмите, чтобы развернуть…

Ответ: да, Лу Костелло был забавным с Бадом Эбботтом или без него. Не то чтобы я не соглашался ни с чем, что вы сказали, но в любом случае это было да, Лу был просто забавным парнем, а его прямой человек был лучшим в бизнесе, что усиливало его забавность. Дин Мартин также приходит на ум как фантастический натурал, когда он был частью комедийной команды Мартина и Льюиса. Дин был настолько уравновешенным, что люди не понимали, насколько он важен для динамики команды.
Между прочим, самое интересное в Эбботте и Костелло то, что Бад Эбботт был прямым сотрудником, наемным работником на зарплате Костелло. Костелло был боссом и мозгом дуэта, и он руководил их карьерой вместе с тем, что, по общему мнению, было железным кулаком. Нужно быть очень умным, чтобы играть в этого тупого.
Нужно быть очень умным, чтобы играть в этого тупого.
Блэки
Запрещено
#7
[ame=http://www.youtube.com/watch?v=f7pMYHn-1yA]Эбботт и Костелло: «Две десятки на пятерку» — YouTube[/ame]
Ловай
Все дело в Маосе
#8
шлепок сказал:
Нажмите, чтобы развернуть.
 ..
..Ты парень, для которого нет шуток, пока кто-то не получит пирог в лицо или не упадет с лестницы.
3 Балбесы, но без всяких тонкостей и нюансов.
tdearn
Старший член
#9
Вероятно, для вас, ребята, за океаном это ничего не значит, но Эрни Уайз был отличным прямым человеком.
СтивГанги
#10
Было несколько замечательных дуэтов, и они дали нам несколько отличных вещей, а некоторые натуралы, такие как Дин Мартин, сами были чертовски забавны, когда хотели.
[ame=http://www.youtube.com/watch?v=kTcRRaXV-fg]Abbott & Costello Who's On First – YouTube[/ame]
[ame=http://www. youtube.com/watch?v=C-cAmogea4o]Дин Мартин и Джерри Льюис — Веселая библиотечная пародия — Кляп — YouTube[/ame]
[ame=http://www.youtube.com/watch?v=4bmCg_o8mAU ]Стэн Лорел и Оливер Харди: Фортепиано — YouTube[/ame]
данохат
Старший член
#11
Я делаю все, что могу.
Ловай
Все дело в Маосе
#12
Чувак может разменять на 9долларовую купюру и при этом оставаться натуралом.*
Не путать с Top Men™.
Митвад
Старший член
№13
[ame=http://www. youtube.com/watch?v=CiywOTiRPkE]Дай мне птичку! – Сказка о двух котятах – YouTube[/ame]
youtube.com/watch?v=CiywOTiRPkE]Дай мне птичку! – Сказка о двух котятах – YouTube[/ame]
Ханк
Запрещено
№14
Если эта тема посвящена бутылке 5W-30, то я не в этом.
ЭДС1275
Запрещено
№15
Интернет-форумы, подобные этому, здесь, например, предоставляют тонны прямого материала для болтовни в кресле.
Ханк
Запрещено
№16
EDS1275 сказал:
интернет-форумов, подобных этому, здесь, например, предоставляет тонны прямого материала для виляния в кресле.
Нажмите, чтобы развернуть…
Что такое «вага»? Как я могу узнать, являюсь ли я одним из них?
ЭДС1275
Запрещено
# 17
Ханк сказал:
Что такое «шутник»? Как я могу узнать, являюсь ли я одним из них?
Нажмите, чтобы развернуть…
в США, человек с чувством юмора.
если нужно спросить……
Вы должны войти или зарегистрироваться, чтобы ответить здесь.
Повторное посещение Whos On First
- SteveGangi
- За кулисами
- Ответы
- 2
- просмотров
- 221
Митвад
Думаю, мне нужно опубликовать это (более важное внимание, шлюха)
- Electric_Sunshine
- За кулисами
2
- Ответы
- 37
- просмотров
- 2К
19 апреля 2010 г.
- Ответы
- 7
- просмотров
- 535
RedSkwirrell
Мне нужен кто-то, кто поможет мне разобраться в моих фактах…
- noNameUsername
- Лес Полы Эпифон
2
- Ответы
- 34
- просмотров
- 2К
Дэвис
Сказки о ките Фредди и не только Хлам!
- Тим Феззивиг
- За кулисами
- Ответы
- 6
- просмотров
- 362
Тим Феззивиг
Делиться:
Фейсбук
Твиттер
Реддит
Пинтерест
Тамблер
WhatsApp
Эл. адрес
Делиться
Ссылка на сайт
Верх
Носят ли натуралы стринги?
JavaScript отключен. Для лучшего опыта, пожалуйста, включите JavaScript в вашем браузере, прежде чем продолжить.
1 — 20 из 42 сообщений
Стью
·
Зарегистрировано
Броданк
·
Зарегистрировано
ОстинФорестер
·
Зарегистрировано
Сэм О Нела
·
, потому что я могу.
4doorYooper
·
Прекрати глазеть на меня, чувак!
Кислотный
·
Зарегистрировано
QBoroLegend
·
Зарегистрировано
Сэм О Нела
·
, потому что я могу.
